LiteFS の仕組みについて読み解いてみました。 今回はFUSEとノード間の同期処理周りを読んでみました。
ReplicaはPrimaryにHTTPで問い合わせを行い(ロングポーリング)、ユーザはFUSE経由でPrimaryのSQLite3ファイルにアクセスします。 DMLが発行されるとファイルの書き込みが走るのでdirtyPageとしてマーキングしておき、COMMITしたらdirtyPageの情報を使って差分のページ領域をまとめたLTXファイルをReplicaに送ります。 Replicaは返されたLTXファイルを使って差分のページ領域を更新します。
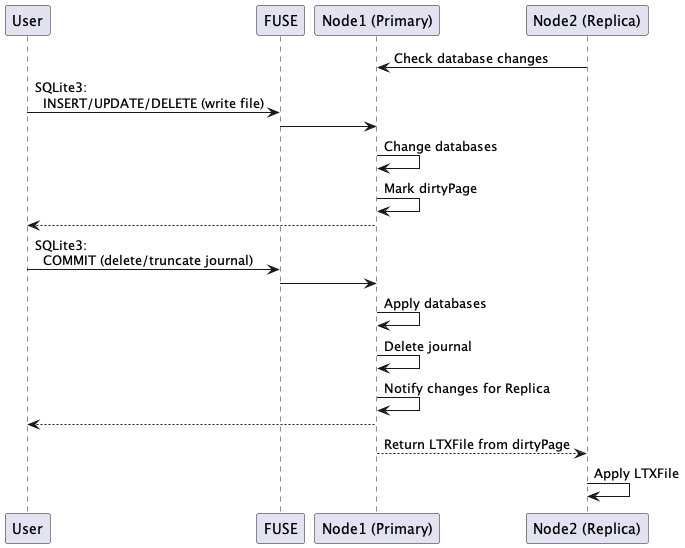
FUSEの処理
Filesystem.Mount() でFUSEを使ったマウントを行います。v0.1.0の時点では hanwen/go-fuse を使っていますが、masterの最新では bazil/fuse を使っています。
// Mount mounts the file system to the mount point.
func (fs *FileSystem) Mount() (err error) {
// Create FUSE server and mount it.
fs.server, err = fuse.NewServer(fs, fs.path, &fuse.MountOptions{
Name: "litefs",
Debug: fs.Debug,
EnableLocks: true,
SingleThreaded: true, // TODO: Remove; Release() is causing an unexpected race error
})
if err != nil {
return err
}
go fs.server.Serve()
return fs.server.WaitMount()
}
fuse.NewServerの第一引数でFUSEのハンドラーとして RawFileSystem のinterfaceをセットしています。
FUSEでマウントしたディレクトリ内のファイルを開くときは FileSystem.Open()
が呼ばれ、ファイル読み込みのときは FileSystem.Read()
といった感じでFileSystemの関数が呼ばれます。
SQLite3のファイルを開いたときは FileSystem.openDBFile()
が呼ばれます。開かれるのは ${マウントディレクトリ}/{DB番号}/database のファイルになります。これが操作するSQLite3ファイルの実体になります。
func (fs *FileSystem) openDBFile(cancel <-chan struct{}, input *fuse.OpenIn, out *fuse.OpenOut) (code fuse.Status) {
dbID, fileType, err := ParseInode(input.NodeId)
if err != nil {
log.Printf("fuse: open(): cannot parse inode: %d", input.NodeId)
return fuse.ENOENT
}
db := fs.store.DB(dbID)
if db == nil {
return fuse.ENOENT
}
f, err := os.OpenFile(filepath.Join(db.Path(), FileTypeFilename(fileType)), int(input.Flags), os.FileMode(input.Mode))
if err != nil {
log.Printf("fuse: open(): cannot open file: %s", err)
return toErrno(err)
}
fh := fs.NewFileHandle(db, fileType, f)
out.Fh = fh.ID()
out.OpenFlags = input.Flags
return fuse.OK
}
SQLite3のファイルを読み込む場合は FileSystem.readDBFile() が呼ばれます。読み込み時には特に何も行わないため、Open()で開いたdatabaseファイルのファイルディスクリプタを使って読み込みを行います。
func (fs *FileSystem) readDBFile(cancel <-chan struct{}, input *fuse.ReadIn, buf []byte) (fuse.ReadResult, fuse.Status) {
fh := fs.FileHandle(input.Fh)
if fh == nil {
log.Printf("fuse: read(): bad file handle: %d", input.Fh)
return nil, fuse.EBADF
}
//n, err := fh.File().ReadAt(buf, int64(input.Offset))
//if err == io.EOF {
// return fuse.ReadResultData(nil), fuse.OK
//} else if err != nil {
// log.Printf("fuse: read(): cannot read: %s", err)
// return nil, fuse.EIO
//}
//return fuse.ReadResultData(buf[:n]), fuse.OK
return fuse.ReadResultFd(fh.File().Fd(), int64(input.Offset), int(input.Size)), fuse.OK
}
SQLite3に書き込むときは FileSystem.writeDatabase() が呼ばれます。
func (fs *FileSystem) writeDatabase(cancel <-chan struct{}, fh *FileHandle, input *fuse.WriteIn, data []byte) (written uint32, code fuse.Status) {
if err := fh.DB().WriteDatabase(fh.File(), data, int64(input.Offset)); err != nil {
log.Printf("fuse: write(): database error: %s", err)
return 0, toErrno(err)
}
return uint32(len(data)), fuse.OK
}
DB.WriteDatabase() では実体のdatabaseファイルに書き込みを行います。
func (db *DB) WriteDatabase(f *os.File, data []byte, offset int64) error {
db.mu.Lock()
defer db.mu.Unlock()
// Return an error if the current process is not the leader.
if !db.store.IsPrimary() {
return ErrReadOnlyReplica
} else if len(data) == 0 {
return nil
}
// Use page size from the write.
// TODO: Read page size from meta page.
if db.pageSize == 0 {
db.pageSize = uint32(len(data))
}
// Mark page as dirty.
pgno := uint32(offset/int64(db.pageSize)) + 1
db.dirtyPageSet[pgno] = struct{}{}
// Callback to perform write on handle.
if _, err := f.WriteAt(data, offset); err != nil {
return err
}
return nil
}
Replicaは読み込み専用なので書き込みできないようにバリデーションをしています。
ページごとに同期の管理を行うため、dirtyPageSet に更新したページ番号のキーをセットします。
最後に WriteAt() によって実体のdatabaseファイルの書き込みを行います。
journalモードがDELETEの場合、コミット時にjournalファイルを削除します。 ファイル削除時は FileSystem.Unlink() が呼ばれます。journalファイルの削除は FileSystem.unlinkJournal() でハンドリングされます。
func (fs *FileSystem) unlinkJournal(cancel <-chan struct{}, input *fuse.InHeader, dbName string) (code fuse.Status) {
db := fs.store.DBByName(dbName)
if db == nil {
return fuse.ENOENT
}
if err := db.CommitJournal(litefs.JournalModeDelete); err != nil {
log.Printf("fuse: unlink(): cannot commit journal: %s", err)
return toErrno(err)
}
return fuse.OK
}
DB.CommitJournal()
ではLTXファイルを作成します。 dirtyPageSet を使って更新済みのページのファイル内容をLTXファイルに書き込みます。
LTXファイルの構造はだいたいこんな感じになっています。
────────
LTX Header
────────
Page Header 1
────────
...
────────
Page Header N
────────
Event Header 1
────────
...
────────
Event Header N
────────
Event Data
────────
Page Body 1
────────
...
────────
Page Body N
────────
ちなみにv0.1.0の時点ではEvent HeaderやEvent Dataは未使用。 PageはWriteしたページの領域を指しています。書き込みしたページ領域のみ差分更新するためにこのような構成になっていると思われます。
最後に Store.MarkDirty() を呼び出します。
// MarkDirty marks a database ID dirty on all subscribers.
func (s *Store) MarkDirty(dbID uint32) {
s.mu.Lock()
defer s.mu.Unlock()
s.markDirty(dbID)
}
func (s *Store) markDirty(dbID uint32) {
for sub := range s.subscribers {
sub.MarkDirty(dbID)
}
}
Subscriber.MarkDirty()
では dirtySet にDBIDのキーをセットして、notifyChにメッセージを送信します。
// MarkDirty marks a database ID as dirty.
func (s *Subscriber) MarkDirty(dbID uint32) {
s.mu.Lock()
defer s.mu.Unlock()
s.dirtySet[dbID] = struct{}{}
select {
case s.notifyCh <- struct{}{}:
default:
}
}
notifyChでメッセージが送信されると、PrimaryからReplicaにレスポンスが返されるようになります。
https://github.com/superfly/litefs/blob/v0.1.0/http/server.go#L178-L180
// Continually iterate by writing dirty changes and then waiting for new changes.
for {
// Send pending transactions for each database.
for dbID := range dirtySet {
if err := s.streamDB(r.Context(), w, dbID, posMap); err != nil {
Error(w, r, fmt.Errorf("stream error: db=%s err=%s", litefs.FormatDBID(dbID), err), http.StatusInternalServerError)
return
}
}
// Wait for new changes, repeat.
select {
case <-r.Context().Done():
return
case <-subscription.NotifyCh():
dirtySet = subscription.DirtySet()
}
}
Primary/Replica間のHTTP通信
サーバー側となるPrimaryでは Server.streamDB() を呼び出して、ファイルの差分であるLTXファイルをクライアントであるReplicaに返します。
func (s *Server) streamDB(ctx context.Context, w http.ResponseWriter, dbID uint32, posMap map[uint32]litefs.Pos) error {
db := s.store.DB(dbID)
// Stream database frame if this is the first time we're sending data.
if _, ok := posMap[dbID]; !ok {
log.Printf("send frame<db>: id=%d name=%q", db.ID(), db.Name())
frame := litefs.DBStreamFrame{DBID: db.ID(), Name: db.Name()}
if err := litefs.WriteStreamFrame(w, &frame); err != nil {
return fmt.Errorf("write db stream frame: %w", err)
}
posMap[dbID] = litefs.Pos{}
}
for {
clientPos := posMap[dbID]
dbPos := db.Pos()
// Exit when client has caught up.
if clientPos.TXID >= dbPos.TXID {
return nil
}
newPos, err := s.streamLTX(ctx, w, db, clientPos.TXID+1)
if err != nil {
return fmt.Errorf("stream ltx: pos=%d", clientPos.TXID)
}
posMap[dbID] = newPos
}
}
clientPosやdbPosはトランザクションの位置を表す数値で、トランザクションのたびにインクリメントされます。 実際に返却している処理が Server.streamLTX() です。
最初にサイズを書き込み、その後にLTXファイルを書き込みます。
// Write frame.
frame := litefs.LTXStreamFrame{Size: fi.Size()}
if err := litefs.WriteStreamFrame(w, &frame); err != nil {
return litefs.Pos{}, fmt.Errorf("write ltx stream frame: %w", err)
}
// Write LTX file.
if _, err := w.Write(buf); err != nil {
return litefs.Pos{}, fmt.Errorf("write ltx header: %w", err)
} else if _, err := io.CopyN(w, f, frame.Size-int64(len(buf))); err != nil {
return litefs.Pos{}, fmt.Errorf("write ltx file: %w", err)
}
w.(http.Flusher).Flush()
クライアント側のReplicaでは Store.processLTXStreamFrame() で適用していきます。やっていることとしては Server.streamLTX() の逆で、返されたLTXStreamFrameからLTXファイルを復元してReplicaにLTXファイルを作成し、 DB.TryApplyLTX() を呼び出してそのLTXファイルをReplicaのdatabaseに適用します。