俺もビッグデータの分析とかやってみたいなー →Twitterとか身近なビッグデータっぽくて扱いやすそう →よし、アイドル(坂道シリーズ)に関するツイート集めて分析してみよう
という軽いノリでFluentd + ElasticSearch + Kibanaというよくある構成で分析基盤(?)を作ってみました。
今回は基盤作るまでのインストール&設定地獄の備忘録。(自力でやんなくてもDockerやChefで一発で構築できるモノが出回ってそうですが…)
全体構成
Fluentdのfluent-plugin-twitterを使ってStreamingAPI経由で乃木坂、欅坂に関するデータを取得 →データをElasticSearchにぶん投げる。kuromojiのanalyzerで日本語の形態素解析 →Kibanaでビジュアライゼーションという構成
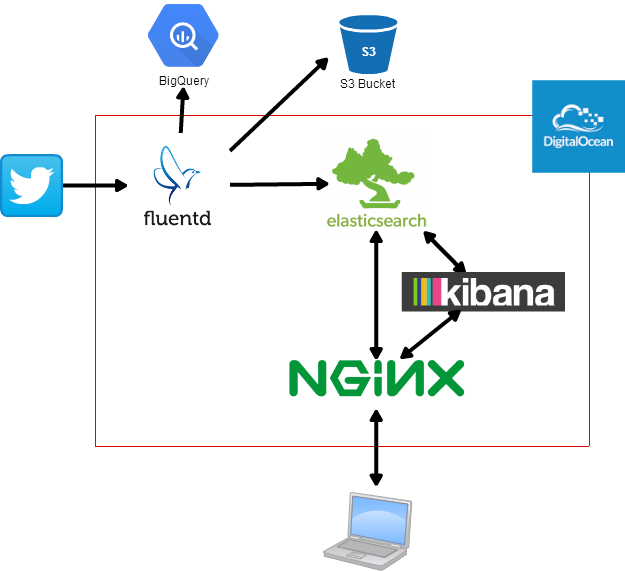
KibanaやElasticSearch自身にも認証機構を持たせることが出来るっぽいですが、設定が面倒だし設定箇所が分散するので、前段にnginxをリバプロとして置いて、nginx側でBasic認証をかけることで認証を一元的に行うようにしました。
スペックは以下のとおり
- OS:Ubuntu 14.04(64bit)
- Platform:DigitalOcean
- Plan:1GB / 1CPU($10)
nginxのインストール&設定
nginxのインストール。Basic認証使うのでhtpasswdコマンドも。$ sudo apt-get install nginx apache2-utils
Basic認証の設定
$ sudo htpasswd -c /etc/nginx/.htpasswd hoge
リバプロとして利用するので以下の様な設定を/etc/nginx/sites-available/defaultとかに記載しておく
server {
listen 443;
server_name localhost;
...
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/.htpasswd;
location / {
try_files $uri $uri/ =404;
}
location /kibana/ {
proxy_pass http://127.0.0.1:5601/;
}
location /es/ {
proxy_pass http://127.0.0.1:9200/;
}
location /sv/ {
proxy_pass http://127.0.0.1:9001/;
}
}
Basic認証かけるとはいえ非SSLは論外だと思いますし、署名付きの証明書が無料で手に入る時代でオレオレ式は微妙だと思ったのでLet’s EncryptでSSL証明書取ってきました。
$ git clone https://github.com/letsencrypt/letsencrypt
$ cd letsencrypt
$ ./letsencrypt-auto certonly --webroot --webroot-path \
/usr/share/nginx/html -d {domain}
証明書取得に関するドメインバリデーションは、既存のWebサーバを使う方法と使わない方法の二種類あり、webroot指定の場合は既存のWebサーバ(今回はnginx)を使う方法になります。ACMEというプロトコルによってバリデーションが行われるようで、webサーバのドキュメントルート内に認証用のファイルを置いて、Let’s Encrypt側で指定されたURL(ドメイン)に対して認証用のファイルを取得&中身の検証が出来れば認証が通り、署名付きの証明書が生成される、というフローになります。
Let’s Encryptを使った場合、nginxの証明書、秘密鍵の指定は以下のようになります。
ssl_certificate /etc/letsencrypt/live/{domain}/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/{domain}/privkey.pem;
Kibanaのインストール&設定
kibanaのダウンロードリンクからソースをダウンロード$ wget -O kibana.tar.gz \
https://download.elastic.co/kibana/kibana/kibana-4.4.1-linux-x64.tar.gz
$ tar zxvf kibana.tar.gz
リバプロしている関係で以下のように{kibana_path}/config/kibana.ymlを書き換えます
server.basePath: "/kibana"
ElasticSearchのインストール・設定
elasticsearchのダウンロードリンクからソースをダウンロード$ wget -O elasticsearch.tar.gz \
https://download.elasticsearch.org/elasticsearch/release/org/elasticsearch/distribution/tar/elasticsearch/2.2.0/elasticsearch-2.2.0.tar.gz
$ tar zxvf elasticsearch.tar.gz
Java無いと動かないのでインストール
$ sudo apt-get install openjdk-7-jdk
日本語の形態素解析をやってくれるkuromojiをインストール
$ {elasticsearch_path}/bin/plugin install analysis-kuromoji
{elasticsearch_path}/config/elasticsearch.ymlで以下のようにデフォルトでkuromojiのtokenizerとpos_filterが効く設定に変更。stoptagsは除外するものをちゃんと指定しないとうまく動かなかったのでズラズラーっと書いてます
index.analysis.analyzer.default.type: custom
index.analysis.analyzer.default.tokenizer: ja_tokenizer
index.analysis.analyzer.default.filter.0: pos_filter
index:
analysis:
filter:
pos_filter:
type: kuromoji_part_of_speech
stoptags: ["接続詞", "助動詞", "助詞", "助詞-格助詞", "助詞-格助詞-一般", "助詞-格助詞-引用", "助詞-格助詞-連語", "助詞-接続助詞", "助詞-係助詞", "助詞-副助詞", "助詞-間投助詞", "助詞-並立助詞", "助詞-終助詞", "助詞-副助詞/並立助詞/終助詞", "助詞-連体化", "助詞-副詞化", "助詞-特殊"]
tokenizer:
ja_tokenizer:
type: kuromoji_tokenizer
mode: search
user_dictionary: userdict_ja.txt
analyzer:
ja:
type: custom
tokenizer: ja_tokenizer
filter:
- pos_filter
{elasticsearch_path}/config/userdict_ja.txtにユーザ辞書を登録しておく。形態素解析の時にここで登録したワードが切り出されます
乃木坂,乃木坂,ノギザカ,カスタム品詞
欅坂,欅坂,ケヤキザカ,カスタム品詞
秋元真夏,秋元真夏,アキモトマナツ,カスタム品詞
生田絵梨花,生田絵梨花,イクタエリカ,カスタム品詞
生駒里奈,生駒里奈,イコマリナ,カスタム品詞
伊藤かりん,伊藤かりん,イトウカリン,カスタム品詞
伊藤純奈,伊藤純奈,イトウジュンナ,カスタム品詞
伊藤万理華,伊藤万理華,イトウマリカ,カスタム品詞
井上小百合,井上小百合,イノウエサユリ,カスタム品詞
衛藤美彩,衛藤美彩,エトウミサ,カスタム品詞
...
管理用のプラグインも一応インストールしておく。無くても動きますが、あると色々便利です。
$ {elasticsearch_path}/bin/plugin install mobz/elasticsearch-head
Fluentdのインストール・設定
Ruby、gemがインストールされている必要があります。インストールされていない場合はrbenv使った方が色々都合が良さそうなので、rbenv経由で以下のようにしてインストールする。$ sudo apt-get install build-essential libreadline-dev #これを入れないとrubyのインストールでこける
$ git clone https://github.com/sstephenson/rbenv.git ~/.rbenv
$ echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.zshrc # bashの場合は.bashrc
$ echo 'eval "$(rbenv init -)"' >> ~/.zshrc
$ source .zshrc
$ git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build
$ rbenv install 2.2.4
$ rbenv global 2.2.4
$ rbenv rehash
あとはfluentd関連のパッケージをgemで入れまくる
$ gem install fluentd \
fluent-plugin-elasticsearch \
fluent-plugin-s3 \
fluent-plugin-record-reformer \
fluent-plugin-twitter --no-ri --no-rdoc
設定ファイルはgistに突っ込んでます。bigqueryも使う場合はfluent-plugin-bigqueryも入れてください。
Supervisorのインストール・設定
kibana、fluentd、elasticsearchはサービスとして登録されていないため、デーモンとして動きません。Supervisorでこれらをデーモン化します。
$ sudo apt-get install python-pip
$ sudo pip install supervisor
設定ファイルは echo_supervisord_conf で自動生成して、サービス毎に設定する感じで。HTTPのインターフェースも設定しておくと便利かも。elasticsearch、kibana、fluentdは以下の様な記述でOKです。設定ファイルの場所はどこでもOKですが、公式で配布されているinitscriptを使う場合は、 /etc/supervisor/supervisord.conf に置くと良いです。
[program:elasticsearch]
command=/home/xxx/elasticsearch/bin/elasticsearch
autostart=true
autorestart=true
user=xxx
redirect_stderr=true
stdout_logfile=/var/log/elasticsearch.log
[program:kibana]
command=/home/xxx/kibana/bin/kibana
autostart=true
autorestart=true
user=xxx
redirect_stderr=true
stdout_logfile=/var/log/kibana.log
[program:fluentd]
command=/home/xxx/.rbenv/shims/fluentd -c /home/xxx/fluentd/fluentd.conf -vvv
autostart=true
autorestart=true
user=xxx
redirect_stderr=true
stdout_logfile=/var/log/fluentd.log
実行ファイルパスは適宜修正する感じで。
pipでインストールした場合はinitscriptを書く必要があります。以下のリンクを参考に/etc/init.d/supervisordのファイルを作成します。(supervisorの実行ファイルパス等は適宜修正)
Supervisor/initscripts: User-contributed OS init scripts for Supervisor
initscriptを書いたらサービス化して起動
$ sudo chmod u+x /etc/init.d/supervisord
$ sudo update-rc.d supervisord defaults
$ sudo service supervisord start
エラーになる場合はinitscriptに記載されているファイルのパスやパーミッションを確認する。
kibanaで見てみる&結果の考察
一日あたりのワードカウントで円グラフを書くとこんな感じ。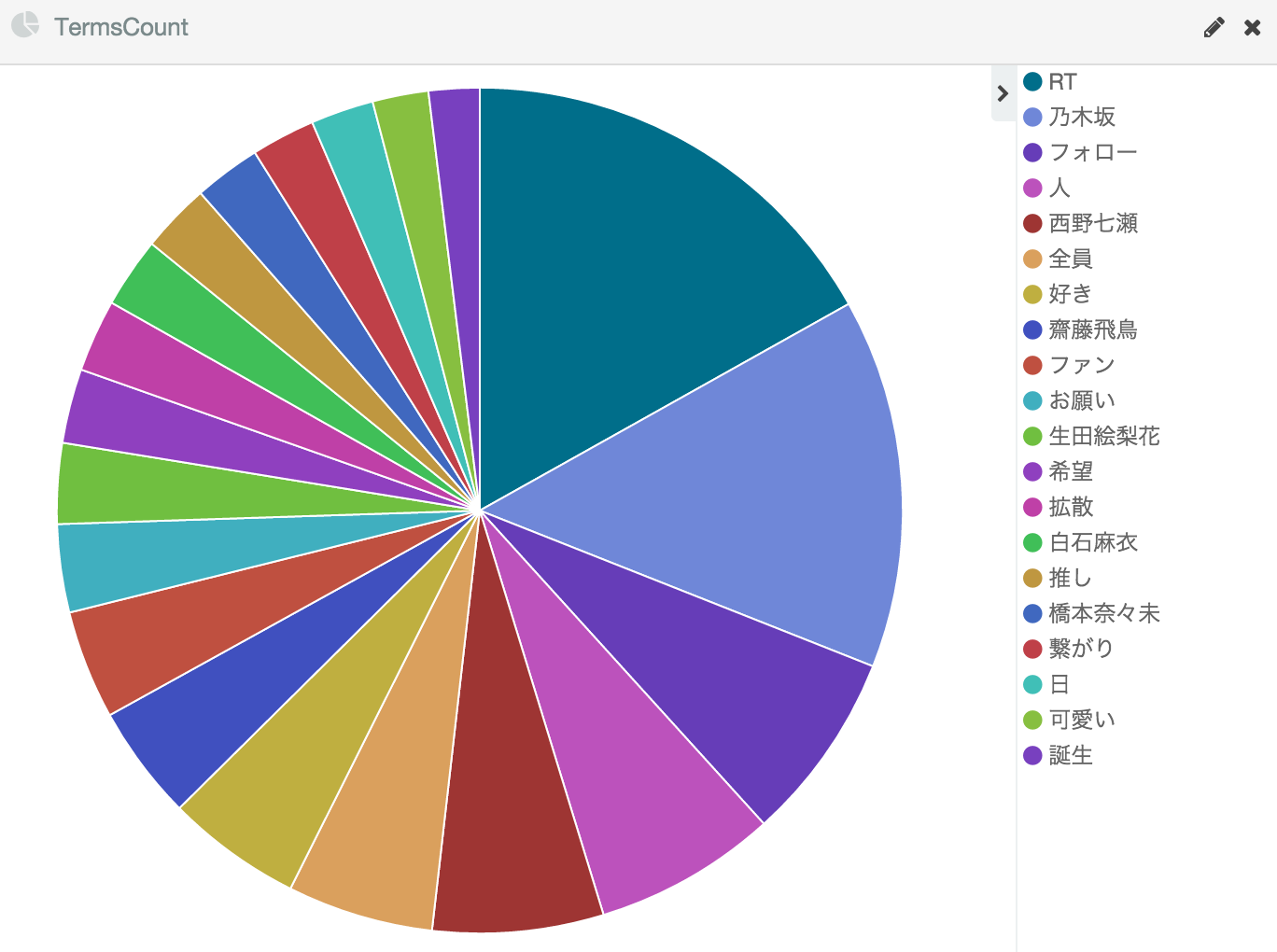
某S社のギガのCMメンバーが強い…。特に西野七瀬は乃木坂メンバー内でのツイート率が常に一位でした(サンプル期間は1日~)。また、上位陣はアイドル好き女子大生が選んだ〝生〟アイドルランキング!!のメンバーと一致しています。
上記設定で収集したら一日あたりのツイート数は27,000程度。S3にJSON全て保存していますが、gzipにして20MB、生データだと一日あたり200MB程度でした。(ツイートの種別?によってサイズが結構変わるので参考値程度で)
「RT」が一位であったり、「拡散」「希望」がほぼ同数で数も多いことから、リツイートして拡散させているようなツイートが非常に多いです。RT以外のツイートはデイリーの27,000ツイート中3,500程度なので8割以上占めている感じです。「相互フォロー」系も多いです。さらに残った3500ツイートもボットが多そうな雰囲気がしているので、もう少し精査が必要そうです。
また、今回はユーザ辞書にグループ名とメンバーの氏名を入れましたが、普通にツイートしててグループ名やメンバーの氏名を書くことは無く(俺感覚)、「白石麻衣」→「まいやん」とアダ名で書いたりすることが多いです。かといって、「まいやん」をキーワードにすると「まいやん」違いで全国のマイさんに関するツイートを拾ってきてしまうし、全員のアダ名を書くとキーワード数が増えてしまうため、キーワードの選定が非常に難しいです。
今後の課題
- ElasticSearch、Kibanaの使い方に習熟し、異なる条件、指標でツイートを分析
- Twitter Streaming APIにおけるキーワード精査
- ツイート自体の精査(RTが含まれるツイートは除外する等)
- ツイート以外の有用なデータの検討
- 全文検索エンジンとは異なるアプローチ(例えばBigQueryやAnalytics Cloud等のカラム指向DB)で分析
- Norikra等のリアルタイム処理を入れて、特定のメンバー、グループに関するツイートが増えた時に通知(何かのイベントが行われている可能性が高い)
参考URL
- Elasticsearch 日本語で全文検索 その2 — Hello! Elasticsearch. — Medium
- Let's Encrypt で手軽に HTTPS サーバを設定する - Qiita
なんかネタで考えて色々やってたらいつの間にかガチになっていた