embulkを使ってTreasure Dataにjsonl形式のデータを流し込んでみました。
データ
- データソース:fluentd経由で取得したTwitterのツイート(Twitter Streaming API)
- 格納先:S3
- データ形式:jsonl
- 圧縮方式:gzip
embulkの設定・実行
インストール方法は本家を参照→embulk/embulk: Embulk: Pluggable Bulk Data Loader. http://www.embulk.org各種プラグインのインストール
$ embulk gem install embulk-input-s3
$ embulk gem install embulk-output-td
$ embulk gem install embulk-filter-typecast
$ embulk gem install embulk-parser-jsonl
config.ymlはこんな感じで
in:
type: s3
bucket: {backet_name}
path_prefix: sakamichi/2016/05/01
endpoint: s3-ap-northeast-1.amazonaws.com
access_key_id:{AWS_ACCESS_KEY_ID}
secret_access_key: {AWS_SECRET_ACCESS_KEY}
decoders:
- {type: gzip}
parser:
type: jsonl
charset: UTF-8
newline: CRLF
columns:
- {name: id_str, type: string}
- {name: text, type: string}
- {name: timestamp_ms, type: string}
- {name: user_id_str, type: string}
- {name: user_name, type: string}
- {name: created_at, type: string}
- {name: user_lang, type: string}
- {name: user_time_zone, type: string}
- {name: place, type: string}
- {name: coordinates, type: string}
- {name: time, type: string}
- {name: tag, type: string}
- {name: lang, type: string}
- {name: geo, type: string}
- {name: retweeted_status_id_str, type: string}
- {name: retweet_count, type: long}
- {name: favorite_count, type: long}
- {name: retweeted, type: boolean}
- {name: favorited, type: boolean}
- {name: source, type: string}
- {name: in_reply_to_status_id_str, type: string}
filters:
- type: typecast
columns:
- {name: timestamp_ms, type: long}
out:
type: td
apikey: {TREASURE_DATA_API_KEY}
endpoint: api.treasuredata.com
database: test_sakamichi
table: test
time_column: timestamp_ms
unix_timestamp_unit: milli
timestamp_msはstringで格納されていて、time_columnで利用するため、long型にキャストします。そのため、typecastフィルタを利用しています。timestampのフォーマットでミリ秒を指定する方法があれば、それで対応する方が良いかも。
TreasureDataのAPIキーは右上のMy profileのAPI Keysから取得します。(上のMaster API keysを利用します)
あとはembulkを実行してインポートするだけ
$ embulk run config.yml
TreasureDataを触ってみる
こんな感じのクエリを書いて実行してみました。;">SELECT
CASE
WHEN retweeted_status_id_str IS NULL THEN 'NOT RT'
ELSE 'RT'
END AS RT_status,
CASE
WHEN text LIKE '%西野七瀬%' THEN TRUE
ELSE FALSE
END AS Is_NishinoNanase,
COUNT(*) AS COUNT
FROM
test
GROUP BY
CASE
WHEN retweeted_status_id_str IS NULL THEN 'NOT RT'
ELSE 'RT'
END,
CASE
WHEN text LIKE '%西野七瀬%' THEN TRUE
ELSE FALSE
END
結果はこんな感じ
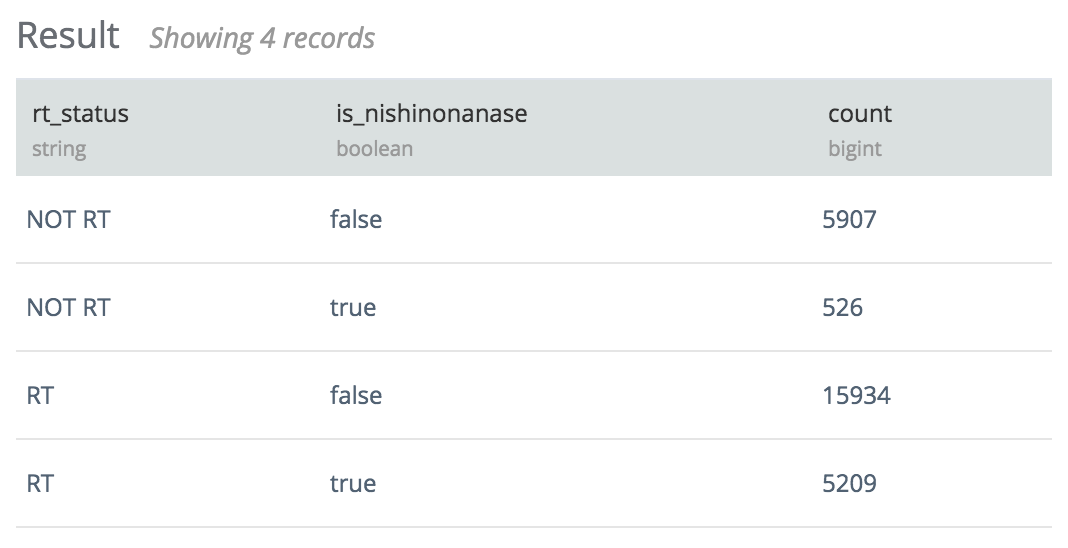
RTで西野七瀬が含まれている率が高い…。きっと「拡散希望、リツイートした人全員フォロー」のアレです。
その他
1ファイルじゃなくて複数ファイルアップロードしようとしたところ、以下のエラーでアップロードできませんでした…。Error: java.lang.RuntimeException: java.io.IOException:
com.treasuredata.client.TDClientProcessingException:
[EXECUTION_FAILURE] java.util.concurrent.TimeoutException
The root cause: java.util.concurrent.TimeoutException
Timeout値を変更するパラメータがまだ実装されていないっぽいので、ローカルで直して試してみよっかなー